

【宣伝】pandasのオススメの本の紹介
このブログでも詳しくpandasの使い方を紹介していますが、体系的に学びたい方や、本の方が良いという方には以下の本をオススメしておきます。

準備
pd.read_csv関数などで読み込んだDataFrameをパッと確認するために、head関数とtail関数の使い方を以下の記事で学んだ。

しかし、head関数やtail関数で確認できるのはDataFrameの先頭と末尾。
もし、先頭と末尾以外の行にデータの特徴が現れていた場合捕捉できない。
例えば、データが時系列順に並んでいるが、途中から、ある列のデータの表し方が変わった場合など。
そこでsample関数を使ってランダムに行を抽出して確認すると良い。
説明のために以下のDataFrameを用意する。「コードでDataFrameを用意する方法」についても別の記事で説明している。
import pandas as pd # ※以降のコードでは省略する
df = pd.DataFrame({
"student_id": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
"name": ["taro", "hanako", "jiro", "fuyumi", "sigeru", "satoshi", "misuzu", "taro", "saburo", "ichiro"],
"math": [50, 68, 90, 35, 49, 77, 88, 91, 80, 100],
"english": [10, 99, 55, 54, 30, 29, 67, 45, 46, 88]
})
df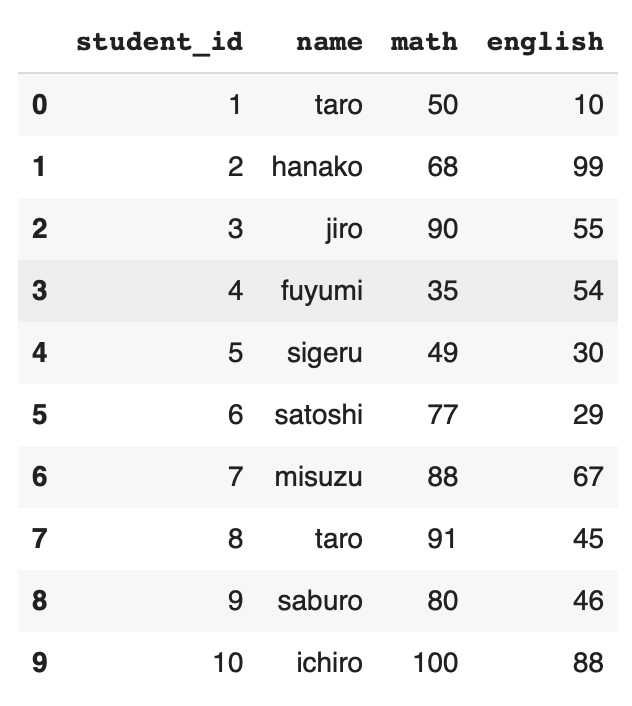
sample関数で行数を指定して抽出する
sample関数に抽出する行数を引数として渡すと、その行数ランダムに抽出される。
※ 引数名は「n」である
df.sample(2) # ランダムに2行抽出
# df.sample(n=2) # もしくはこちら
sample関数で割合を指定して抽出する
sample関数に抽出する割合をfrac引数として渡すと、その割合の行数がランダムに抽出される。
以下の例では、元のDataFrameの行数が10行なので、その30%(0.3)の3行が抽出される。
先ほどの「n」引数との併用は不可。
df.sample(frac=0.3) # 30%抽出する
【Tips】sample関数を使ってDataFrameをランダムに並び替える
先ほどのfracを指定したsample関数を応用してDataFrameをランダムに並び替えることができる。
その場合、fracに1を指定する。
df.sample(frac=1)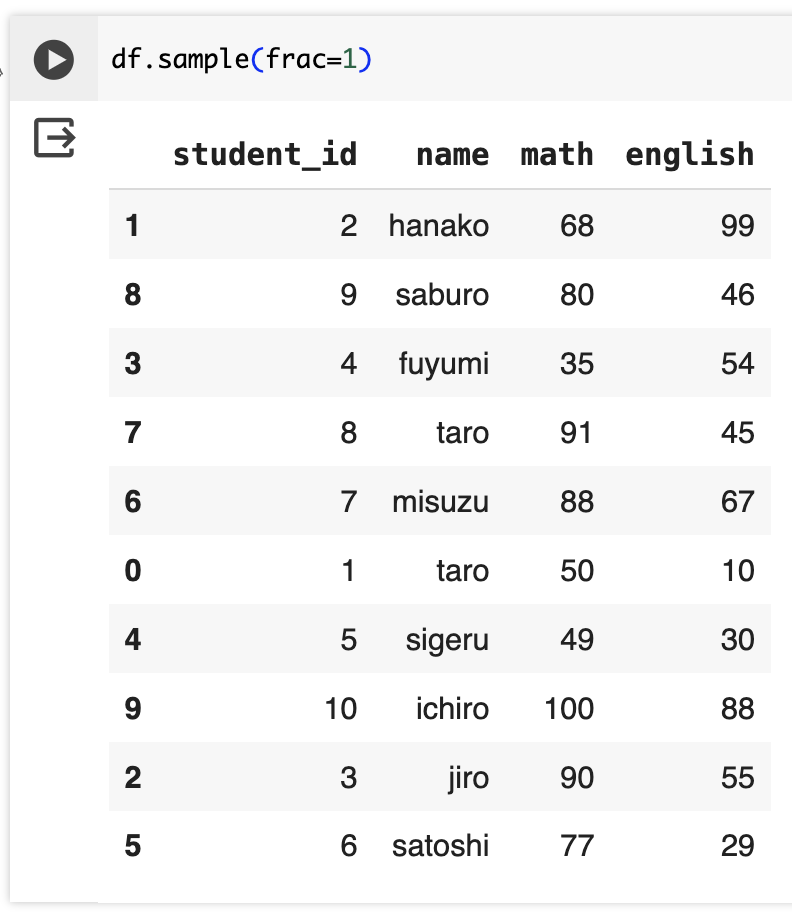
【Tips】ランダムに抽出するが毎回の実行で同じ行を抽出する
ここまでのsample関数の使い方では、コードセルを実行するたびに抽出する行が変わるが、実行のたびに抽出する行を固定するためにはrandom_state引数に好きな数値を指定する。
df.sample(5, random_state=123) # ランダムに5行抽出するが、実行のたびに同じ行を抽出する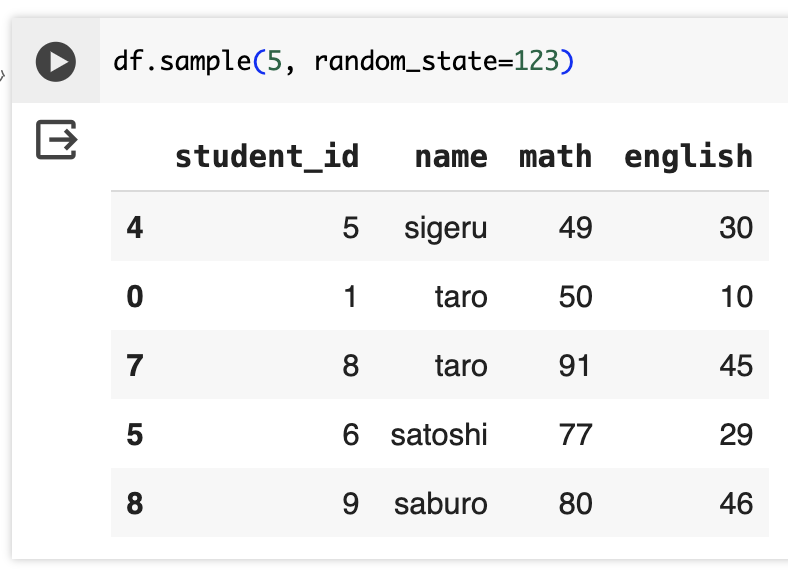
random_stateに別の数値を指定すると、また別のランダムな行が抽出される。
機械学習の際、同じ結果を再現する必要がある場合がある。その時、sample関数のようなランダムな挙動をする関数を使っていると、同じ結果を再現できなくなってしまう。
それを防ぐためにrandom_stateを指定してランダムの挙動が同じになるように制御し、結果を再現する。
このような機能は、ランダムな挙動をする関数には大抵付属しているので調べてみると良い。
Python入門【pandas編】
このブログでは「Python入門【pandas編】」の記事群を整備中です。興味のある方は下のリンク先をチェックしてみてください。

コメント