

【宣伝】pandasのオススメの本の紹介
このブログでも詳しくpandasの使い方を紹介していますが、体系的に学びたい方や、本の方が良いという方には以下の本をオススメしておきます。

DataFrame(データフレーム)とは
pandasを効率良く理解していくために、2つのデータ構造「Series(シリーズ)」と「DataFrame(データフレーム)」を早めに理解すると良い。この記事では「DataFrame」について解説する。
順番としては「Series」から学習した方が良いだろう。「Series」については次の記事で解説した。

DataFrameとは下の画像のような2次元の表形式のデータを扱うデータ構造である。
pandasで最も重要なデータ構造である。
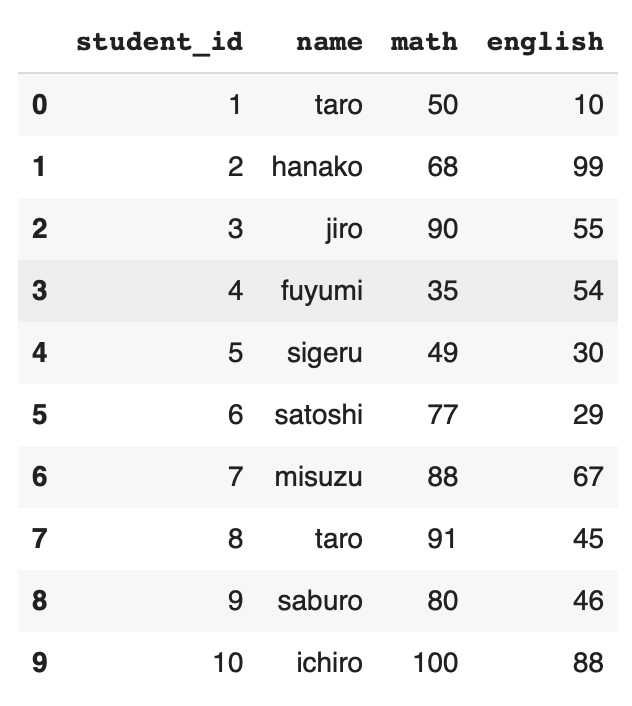
表形式のデータと聞いてピンと来ないかもしれないが、例えばExcelのシートや、データベースのテーブル、CSVファイルなども表形式のデータであり、pandasで扱うことができる。
Pythonの本や、この記事を読むだけで終わるより、実際に実験コードをグーグルコラボなどに書いて色々実験すると良い。以下、基本的なDataFrameを扱うコードを紹介する。
DataFrameを扱うコード
DataFrameをコードで作成する
上の画像で示したDataFrameを作成するコードは下のようになる。
import pandas as pd # ※以降のコードでは省略する
df2 = pd.DataFrame({
"student_id": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
"name": ["taro", "hanako", "jiro", "fuyumi", "sigeru", "satoshi", "misuzu", "taro", "saburo", "ichiro"],
"math": [50, 68, 90, 35, 49, 77, 88, 91, 80, 100],
"english": [10, 99, 55, 54, 30, 29, 67, 45, 46, 88]
})
df2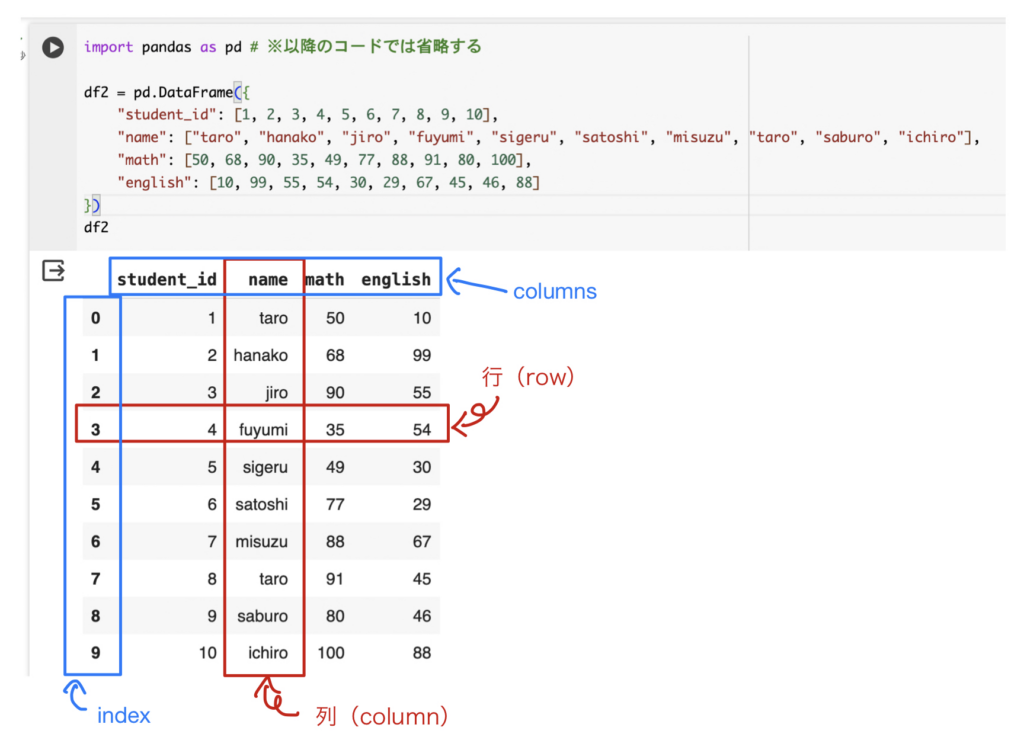
pandasのDataFrameコンストラクタにPythonの辞書を渡してDataFrameを作成する。
DataFrameの挙動について何か確認する時、この方法で手早くテスト用のDataFrameを作成すると良い。(必ずしも10行4列も用意する必要はない。3行2列くらいで十分テストできる)
上の画像で示したように横に並んだ数値 or 文字列1行を行(row)といい、縦に並んだ数値 or 文字列1列を列(column)という。数学の「行列」と同じだ。
また、1番左の列は自動的に割り振られるものでindex(インデックス)といい、各列の1番上の太字の文字列はカラム名といい、それらをまとめてcolumnsという。
DataFrameコンストラクタに渡したPython辞書のキーがカラム名になり、値のリストが列のデータとなる。
DataFrameのindex
上で示したように、DataFrameを作成した際、デフォルトでは0から始まる連番がindexとなる。
df_score = pd.DataFrame({
"name": ["kyosuke", "hikaru", "kyoko"],
"score": [55, 68, 90]
})
df_score.index # indexを出力
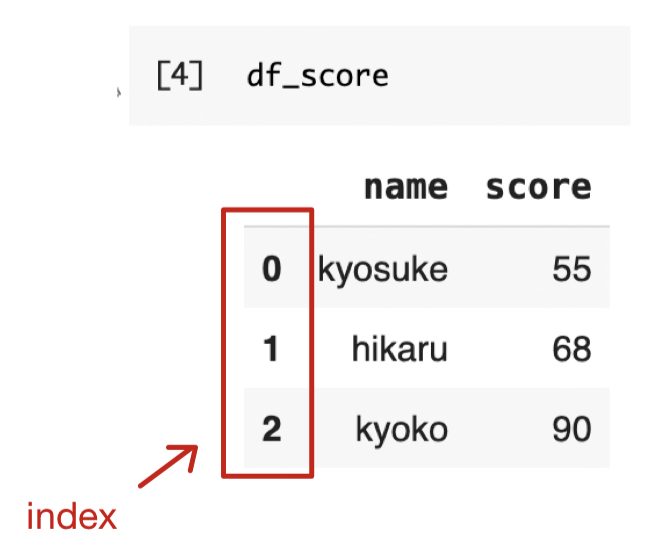
Seriesと同様にDataFrame作成時、indexを指定することで任意のindexにすることができる。
df_score = pd.DataFrame({
"name": ["kyosuke", "hikaru", "kyoko"],
"score": [55, 68, 90]
}, index=["id_1", "id_2", "id_3"])
df_score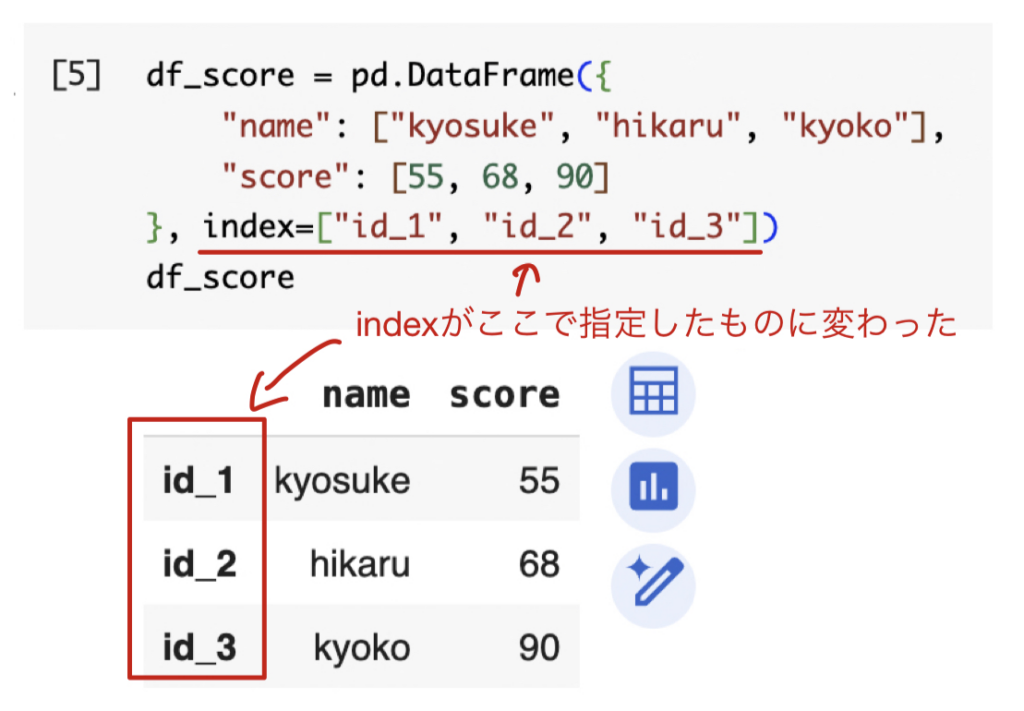
Python入門【pandas編】
DataFrameのより詳しい操作方法は別の記事で解説しています。
下の「Python入門【pandas編】」でpandasに関する記事群の一覧を確認できます。興味のある方は下のリンク先をチェックしてみてください。



コメント