

【宣伝】pandasのオススメの本の紹介
このブログでも詳しくpandasの使い方を紹介していますが、体系的に学びたい方や、本の方が良いという方には以下の本をオススメしておきます。

準備
loc属性, iloc属性を使ってDataFrameの一部を抽出する方法を説明する。
この記事ではloc属性について説明する。
説明のために以下のDataFrameを用意する。「コードでDataFrameを用意する方法」についても別の記事で説明している。
import pandas as pd # ※以降のコードでは省略する
df = pd.DataFrame({
"student_id": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
"name": ["taro", "hanako", "jiro", "fuyumi", "sigeru", "satoshi", "misuzu", "taro", "saburo", "ichiro"],
"math": [50, 68, 90, 35, 49, 77, 88, 91, 80, 100],
"english": [10, 99, 55, 54, 30, 29, 67, 45, 46, 88]
})
df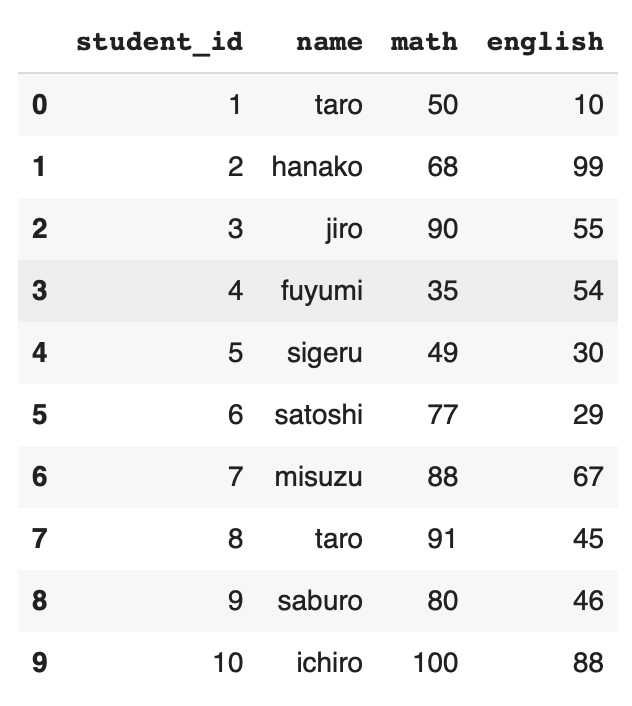
index, columnsを指定して抽出するloc属性
index, columnsの値を使ってDataFrameから一部を抽出することができる。
index, columnsについては以下の記事で解説した。

1行抽出する
loc属性にindexを指定することで該当行を抽出することができる。
df.loc[3] # indexが3の行を抽出する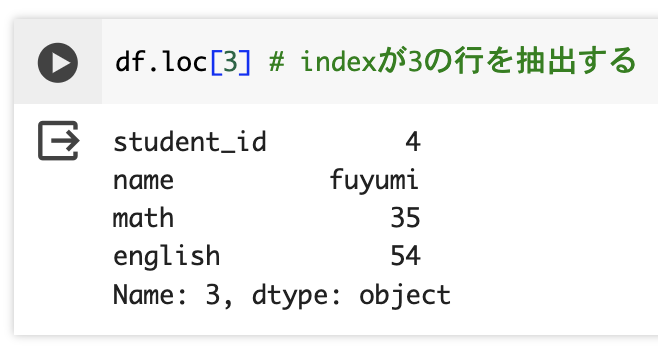
リストを使って複数行抽出する
loc属性にindexのリストを指定することで該当行を抽出することができる。
df.loc[ [0, 8, 2] ] # indexが0,8,2の行を抽出する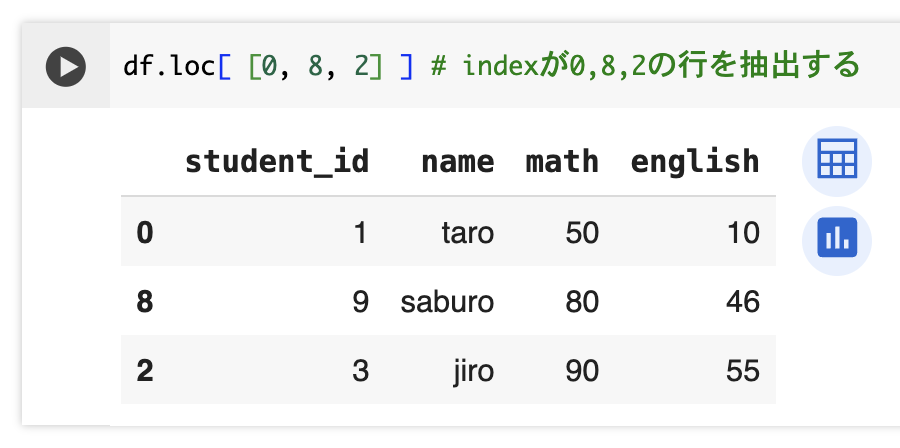
numpyの配列を使って複数行抽出する
loc属性にnumpyの配列を指定することで同様に該当行を抽出することができる。
import numpy as np
arr = np.array([2,7,1])
df.loc[arr]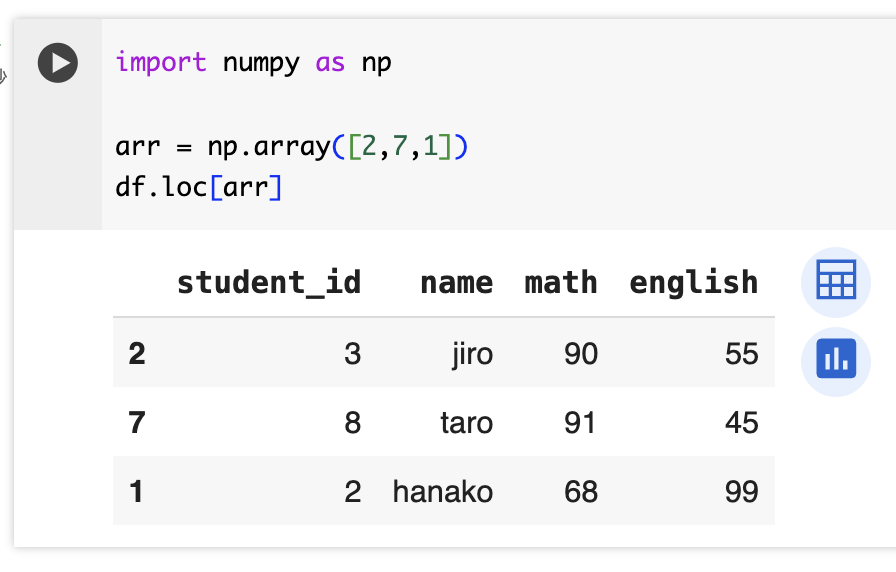
スライスを使って複数行抽出する
別の記事で解説するilocや、一般のPythonのスライスと異なり、locは終端のindexを含んで抽出されることに注意。(終端indexの5の行も抽出される)
注意してないとバグるポイントなので要注意。
df.loc[2:5]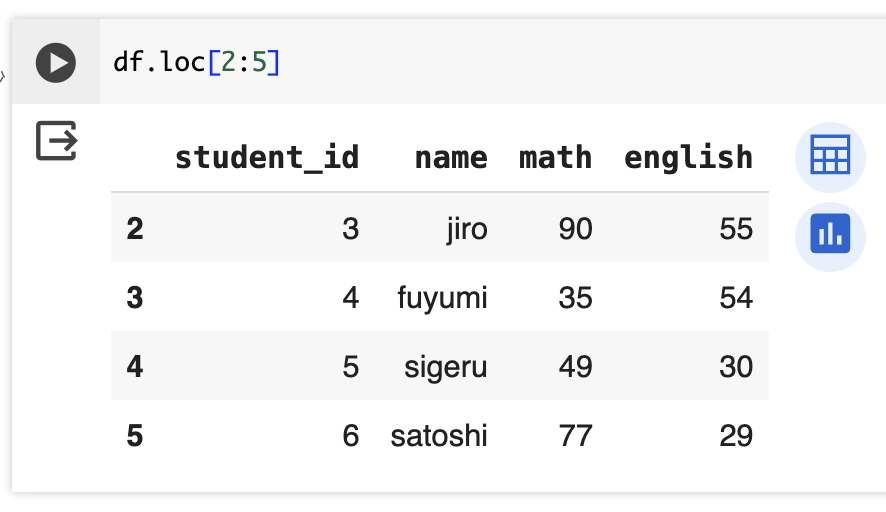
1列抽出する
loc属性はカンマ( , )の前に抽出する行の指定、後ろに抽出する列の指定ができる。
この例のコロン( : )は全行抽出することを意味する。カンマの後ろには抽出する列名を指定する。
df.loc[:, "name"]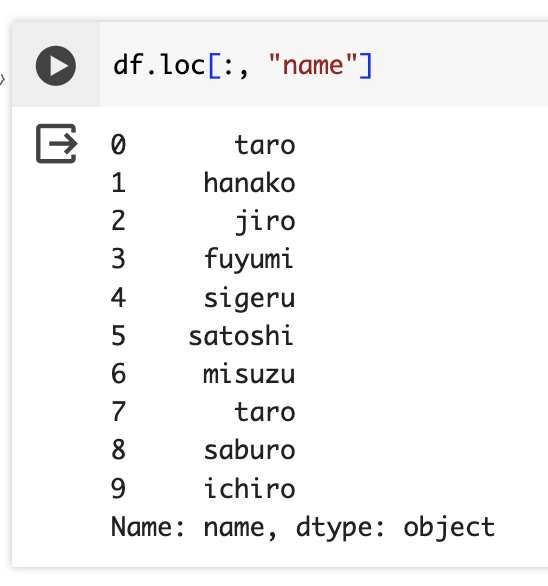
リストを使って複数列抽出する
前節の”name”の部分をカラム名のリストにすることで複数列抽出できる。
df.loc[:, ["name", "math", "english"]]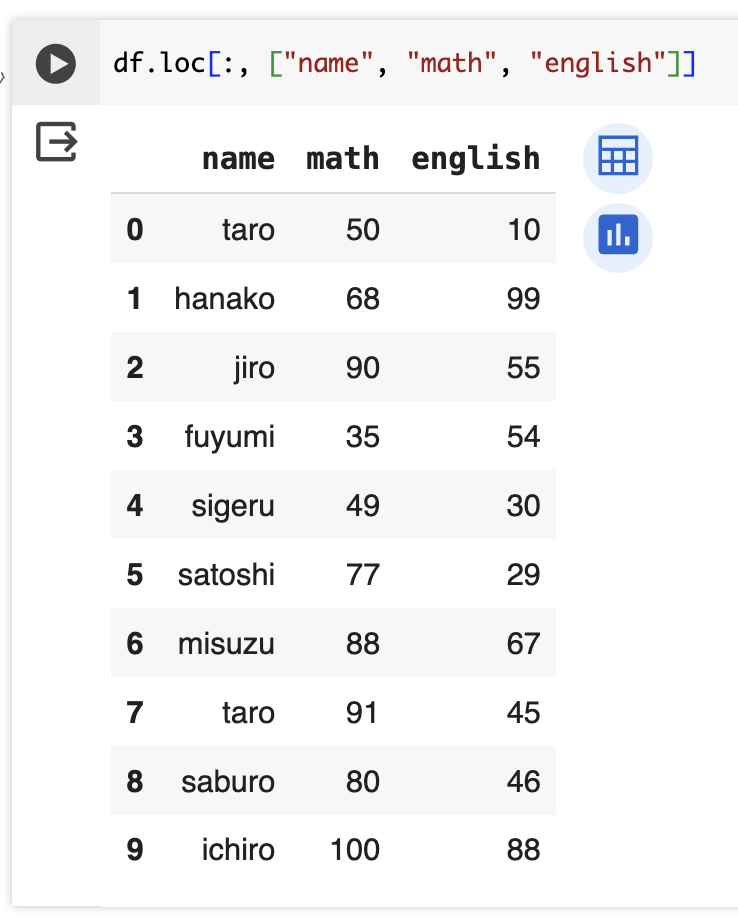
Python入門【pandas編】
このブログでは「Python入門【pandas編】」の記事群を整備中です。興味のある方は下のリンク先をチェックしてみてください。

コメント