


【宣伝】pandasのオススメの本の紹介
このブログでも詳しくpandasの使い方を紹介していますが、体系的に学びたい方や、本の方が良いという方には以下の本をオススメしておきます。

indexとcolumnsとは
pandasの「index」とは、下の画像のようにDataFrame(もしくはSeries)の左側に表示される行を特定するための連番のことです。(※ 連番ではなく文字列にすることもできます)
「columns」とは、下の画像のようにDataFrameの上側に表示される列を特定するためのカラム名のことです。
indexとcolumnsは下のコードのようにデータフレームオブジェクト.index、データフレームオブジェクト.columns で確認することができます。
df_score = pd.DataFrame({
"name": ["kyosuke", "hikaru", "kyoko"],
"score": [55, 68, 90]
})
print(df_score.index)
print(df_score.columns)
index、columnsを使って行・列を抽出する
解説用に下のサンプルDataFrameを使う。
df = pd.DataFrame({
"student_id": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
"name": ["taro", "hanako", "jiro", "fuyumi", "sigeru", "satoshi", "misuzu", "taro", "saburo", "ichiro"],
"math": [50, 68, 90, 35, 49, 77, 88, 91, 80, 100],
"english": [10, 99, 55, 54, 30, 29, 67, 45, 46, 88]
})
df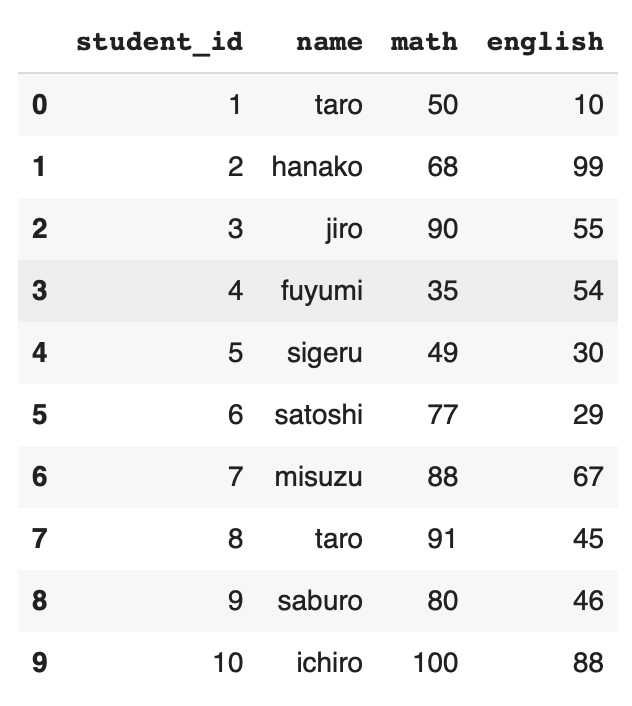
DataFrameの行を抽出する
indexの値を使って行を抽出するにはloc属性を使う。
df.loc[2] # indexの値が2の行を抽出する
上の表のindexの値が2の行と見比べてみて欲しい。
ちなみに、このように抽出した行はSeriesとなる。これはtype関数を使って確認できる。
type(df.loc[2]) # 抽出した行の型を確認する
DataFrameの列を抽出する
columnsの値を使って列を抽出するのは簡単だ。次のように指定する。
df["name"] # []の中にカラム名を指定する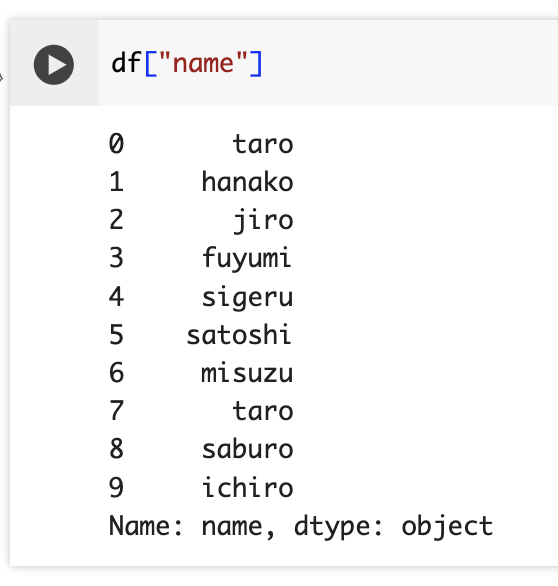
上の表のname列と見比べてみて欲しい。
ちなみに、このように抽出した列もSeriesとなる。type関数で確認できる。
type(df["name"]) # 抽出した列の型を確認する
Python入門【pandas編】
このブログでは「Python入門【pandas編】」の記事群を整備中です。興味のある方は下のリンク先をチェックしてみてください。

コメント